
小对象存储
对于小对象,直接将数据交由 map 保存,远比用指针高效。这不但减少了堆内存分配,关键还在于垃圾回收器不会扫描非指针类型 key/value 对象。
Map空间回收
map 不会收缩 “不再使用” 的空间。就算把所有键值删除,它依然保留内存空间以待后用。
如果一个非常大的map里面的元素很少的话,可以考虑新建一个map将老的map元素手动复制到新的map中。
update if not exists
可以使用遍历的方式,但是时间复杂度会是哈希进行存储及操作,时间复杂度是O(1),样例如下
1 | set := make(map[int]struct{}) |
其中使用空的struct可以规避空间分配,int可以替换为其他类型。
Slice是否相等比较
reflect方法
1 | func StringSliceReflectEqual(a, b []string) bool { |
使用反射的方法进行对比,效率低下,但是代码简单
循环遍历进行比较
1 | func StringSliceEqual(a, b []string) bool { |
BCE 优化版
1 | func StringSliceEqualBCE(a, b []string) bool { |
分布式锁
基于redis的setnx锁
1 | package main |
竞争型的锁,不阻塞,失败时不执行。setnx很适合在高并发场景下,用来争抢一些“唯一”的资源。
基于ZK的锁
1 | package main |
这种分布式的阻塞锁比较适合分布式任务调度场景,但不适合高频次持锁时间短的抢锁场景。
ETCD锁
1 | package main |
三种锁的区别
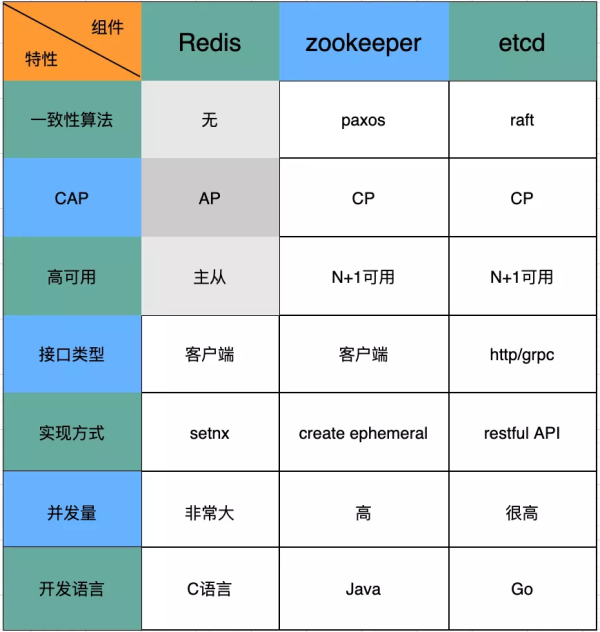
由上图可以看出三种组件各自的特点,其中对于分布式锁来说至关重要的一点是要求CP。但是,Redis集群却不支持CP,而是支持AP。虽然,官方也给出了redlock的方案,但由于需要部署多个实例(超过一半实例成功才视为成功),部署、维护比较复杂。所以在对一致性要求很高的业务场景下(电商、银行支付),一般选择使用zookeeper或者etcd。对比zookeeper与etcd,如果考虑性能、并发量、维护成本来看。由于etcd是用Go语言开发,直接编译为二进制可执行文件,并不依赖其他任何东西,则更具有优势。
Sync.Map
Struct
1 | type Map struct { |
Store
1 | func (m *Map) Store(key, value interface{}) { |
Load/Read
1 | func (m *Map) Load(key interface{}) (value interface{}, ok bool) { |
Delete
1 | func (m *Map) Delete(key interface{}) { |
Go 字符串查找效率问题
问题描述
Golang从字符串查找时,strings.Contains 与 正则对比
以下为查找函数
1 | # strings.Contains |
以下为benchmark函数
1 | const letterBytes = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ" |
正则Benchmark
1 | goos: windows |
strings.Contains Benchmark输出
1 | goos: windows |
可见strings.Contains性能好于使用这种方式的正则匹配判断。
由上面的代码又引发出一个可能更为常见的对比场景,那就是所需的正则是固定的,而所进行对比的字符串不固定,即*regexp.Regexp只生成一次,由此再次进行对比
此时的正则查找函数变为
1 | var reg = regexp.MustCompile("(" + "测试test" + ")") |
得结果如下
1 | goos: windows |
可见strings.Contains性能仍然占上风,因此推荐只在做严格匹配时使用正则,其他场合能用strings.Contains解决尽量不采用正则,以提高效率。